What is Kubernetes Scheduling?
- The Kubernetes Scheduler is a core component of Kubernetes: After a user or a controller creates a Pod, the Kubernetes Scheduler, monitoring the Object Store for unassigned Pods, will assign the Pod to a Node. Then, the Kubelet, monitoring the Object Store for assigned Pods, will execute the Pod.
what is the scheduler for?
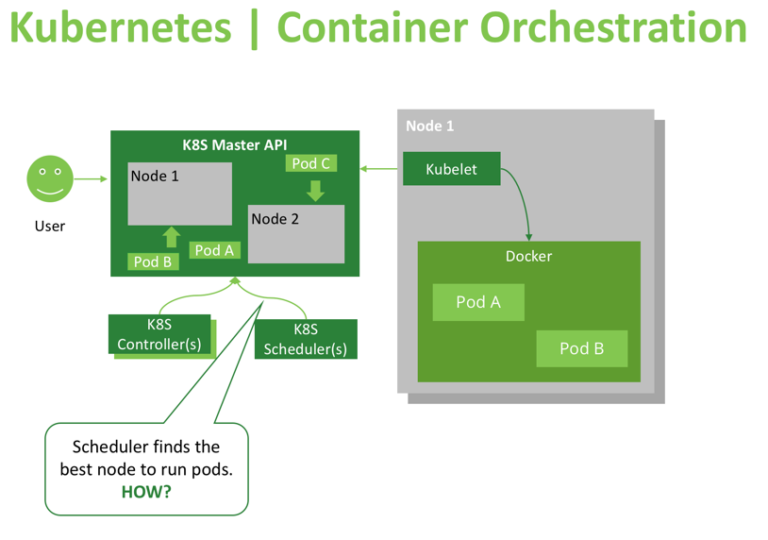
The Kubernetes scheduler is in charge of scheduling pods onto nodes. Basically it works like this:
- You create a pod
- The scheduler notices that the new pod you created doesn’t have a node assigned to it
- The scheduler assigns a node to the pod
It’s not responsible for actually running the pod – that’s the kubelet’s job. So it basically just needs to make sure every pod has a node assigned to it. Easy, right?
What is node affinity ?
- In simple words this allows you to tell Kubernetes to schedule pods only to specific subsets of nodes.
- The initial node affinity mechanism in early versions of Kubernetes was the nodeSelector field in the pod specification. The node had to include all the labels specified in that field to be eligible to become the target for the pod.
nodeSelector Example
First is to give the node a label
kubectl label nodes node1 mynode=worker-1
Next is to create a pod and specify the node via the label
Lets create a pod
$ vi pod.yml
apiVersion: v1 #version of the API to use
kind: Pod #What kind of object we're deploying
metadata: #information about our object we're deploying
name: nginx #Name of the pod
labels: #A tag on the pod created
env: test
spec: #specifications for our object
containers:
- name: nginx #the name of the container within the pod
image: nginx #which container image should be pulled
imagePullPolicy: IfNotPresent #image pull policy
nodeSelector: #Nodeselector condition
mynode: worker-1 # label on the node where pod is going to deploy
Then
kubectl apply -f pod.yml
This will create a pod and will deploy it on the node with label mynode=worker-1
Viewing Your Pods
kubectl get pods --output=wide
[node1 Scheduler101]$ kubectl describe po nginx
Name: nginx
Namespace: default
Priority: 0
PriorityClassName: <none>
Node: node2/192.168.0.17
Start Time: Mon, 30 Dec 2019 16:40:53 +0000
Labels: env=test
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{},"labels":{"env":"test"},"name":"nginx","namespace":"default"},"spec":{"contai...
Status: Pending
IP:
Containers:
nginx:
Container ID:
Image: nginx
Image ID:
Port: <none>
Host Port: <none>
State: Waiting
Reason: ContainerCreating
Ready: False
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-qpgxq (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
default-token-qpgxq:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-qpgxq
Optional: false
QoS Class: BestEffort
Node-Selectors: mynode=worker-1
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 7s default-scheduler Successfully assigned default/nginx to node2
Normal Pulling 3s kubelet, node2 Pulling image "nginx"Deleting the Pod
kubectl delete -f pod.yml
pod "nginx" deleted
Node affinity
Node affinity is conceptually similar to nodeSelector – it allows you to constrain which nodes your pod is eligible to be scheduled on, based on labels on the node.
There are currently two types of node affinity.
- requiredDuringSchedulingIgnoredDuringExecution (Preferred during scheduling, ignored during execution; we are also known as “hard” requirements)
- preferredDuringSchedulingIgnoredDuringExecution (Required during scheduling, ignored during execution; we are also known as “soft” requirements)
Hands On: First Label the Nodes(any two Nodes u have my ex node2, node3)
kubectl label nodes node2 mynode=worker-1
kubectl label nodes node3 mynode=worker-3Then create ur pod
$ vi pod.yml
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: mynode
operator: In
values:
- worker-1
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: mynode
operator: In
values:
- worker-3
containers:
- name: nginx
image: nginx
Then create
kubectl apply -f pod.yml
Viewing Your Pods
kubectl get pods --output=wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
with-node-affinity 1/1 Running 0 9m46s 10.44.0.1 kube-slave1 <none> <none>
[node1 Scheduler101]$ kubectl describe po
Name: with-node-affinity
Namespace: default
Priority: 0
PriorityClassName: <none>
Node: node3/192.168.0.16
Start Time: Mon, 30 Dec 2019 19:28:33 +0000
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{},"name":"with-node-affinity","namespace":"default"},"spec":{"affinity":{"nodeA...
Status: Pending
IP:
Containers:
nginx:
Container ID:
Image: nginx
Image ID:
Port: <none>
Host Port: <none>
State: Waiting
Reason: ContainerCreating
Ready: False
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-qpgxq (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
default-token-qpgxq:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-qpgxq
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 26s default-scheduler Successfully assigned default/with-node-affinity to node3
Normal Pulling 22s kubelet, node3 Pulling image "nginx"
Normal Pulled 20s kubelet, node3 Successfully pulled image "nginx"
Normal Created 2s kubelet, node3 Created container nginx
Normal Started 0s kubelet, node3 Started container nginx
Step Cleanup
Finally you can clean up the resources you created in your cluster:
kubectl delete -f pod.yml

















