Helm is a package manager for Kubernetes applications. In this tutorial, we'll understand the basics of Helm and how they form a powerful tool for working with Kubernetes resources.
Over the past years, Kubernetes has grown tremendously, and so has the ecosystem supporting it. Recently, Helm has been awarded the graduated status by Cloud Native Computing Foundation (CNCF), which shows its growing popularity amongst Kubernetes users.
2. Although these terms are fairly common these days, particularly amongst those working with cloud technologies, let's go through them quickly for those unaware:
- Container: Container refers to operating system-level virtualization. Multiple containers run within an operating system in isolated user spaces. Programs running within a container have access only to resources assigned to the container.
- Docker: Docker is a popular program to create and run containers. It comes with Docker Daemon, which is the main program managing containers. Docker Daemon offers access to its features through Docker Engine API, used by Docker Command-Line Interface (CLI). Please refer to this article for a more detailed description of Docker.
- Kubernetes: Kubernetes is a popular container orchestration program. Although it's designed to work with different containers, Docker is most often used. It offers a wide selection of features, including deployment automation, scaling, and operations across a cluster of hosts. There is excellent coverage of Kubernetes in this article for further reference
Helm Architecture
Helm 2 was primarily on a client-server architecture that comprises of a client and an in-cluster server:
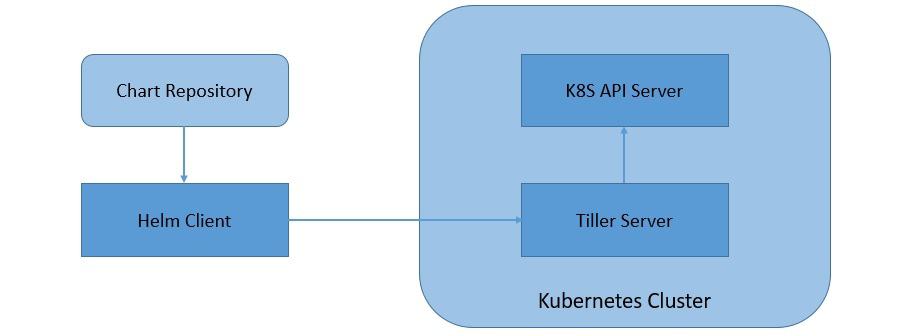
- Tiller Server: Helm manages the Kubernetes application through Tiller Server installed within a Kubernetes cluster. Tiller interacts with the Kubernetes API server to install, upgrade, query, and remove Kubernetes resources.
- Helm Client: Helm provides a command-line interface for users to work with Helm Charts. It is responsible for interacting with the Tiller server to perform various operations like install, upgrade and rollback charts.
Helm 3 has moved onto a completely client-only architecture, where the in-cluster server has been removed:
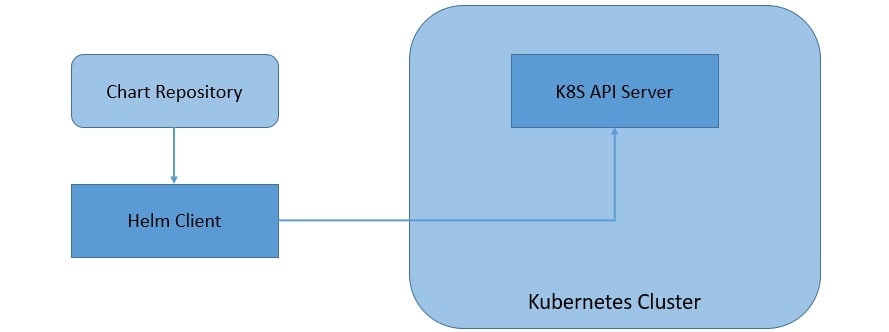
As we can see, the client in Helm 3 works pretty much the same but interacts directly with the Kubernetes API server instead of the Tiller server. This move has simplified the architecture of Helm and allowed it to leverage the Kubernetes user cluster security.
4. Helm Charts, Releases, and Repositories
We'll see more about charts and the changes in Helm 3 as we create them shortly. But for now, a chart is nothing but a set of information necessary to create a Kubernetes application, given a Kubernetes cluster:
- A chart is a collection of files organized in a specific directory structure
- The configuration information related to a chart is managed in the configuration
- Finally, a running instance of a chart with a specific config is called a release
Helm 3 also introduced the concept of library charts. Basically, library charts enable support for common charts that we can use to define chart primitives or definitions. This can help to share snippets of code that we can re-use across charts.
Helm tracks an installed chart in the Kubernetes cluster using releases. This allows us to install a single chart multiple times with different releases in a cluster. Until Helm 2, releases were stored as ConfigMaps or Secrets in the cluster under the Tiller namespace. Starting with Helm 3, releases are stored as Secrets by default in the namespace of the release directly.
Finally, we can share charts as archives through repositories. It is basically a location where packages charts can be stored and shared. There is a distributed community chart repository by the name Artifact Hub where we can collaborate. We can also create our own private chart repositories. We can add any number of chart repositories to work with.
5. Prerequisite: Install K3s
Helm
Let’s get this out of the way. This is the easy stuff. We are going to pretty much follow the official guide, since Helm supports arm64. https://helm.sh/docs/intro/install/
More info about Helm 3: https://helm.sh/docs/
#Make sure GIT is installed apt -y install git #We need to fix kubeconfig file for helm to stop complaining export KUBECONFIG=~/.kube/config mkdir ~/.kube 2> /dev/null sudo k3s kubectl config view --raw > "$KUBECONFIG" chmod 600 "$KUBECONFIG" echo "KUBECONFIG=$KUBECONFIG" >> /etc/environment #Switch to home directory cd #Create a directory for helm mkdir helm #Switch to helm directory cd helm #Download helm installer curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 #change permissions to execute chmod 700 get_helm.sh #install helm ./get_helm.sh #check if helm is installed root@control01:~/helm# helm version version.BuildInfo{Version:"v3.11.0", GitCommit:"472c5736ab01133de504a826bd9ee12cbe4


